vllm-metal vs mlx_lm: Contiguous vs Paged Varlen KV Cache
The mlx_lm case study: 2.5× on a 32GB Mac, ~free on a 64GB Mac
Same mlx_lm code, two Macs, no other changes. Three prompts of 30K + 5K + 10 input tokens (Qwen3-0.6B, max_tokens=256), run first sequentially then concurrently. On the M1 Max 64GB the concurrent run finishes in 45.0s, against 40.3s sequential. On the M1 Pro 32GB the concurrent run takes 189.6s, against 74.8s sequential. No OOM, no crash, no warning.
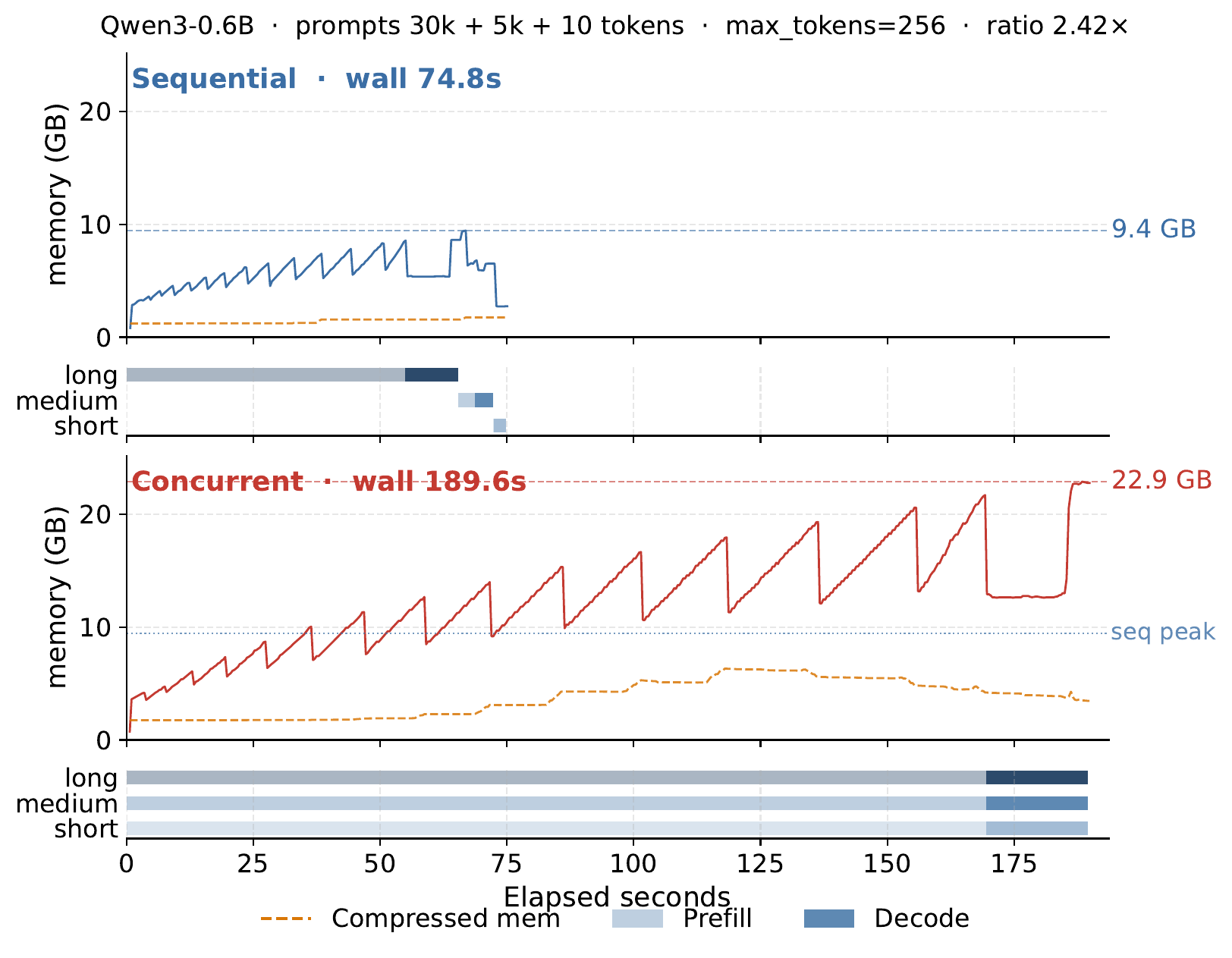
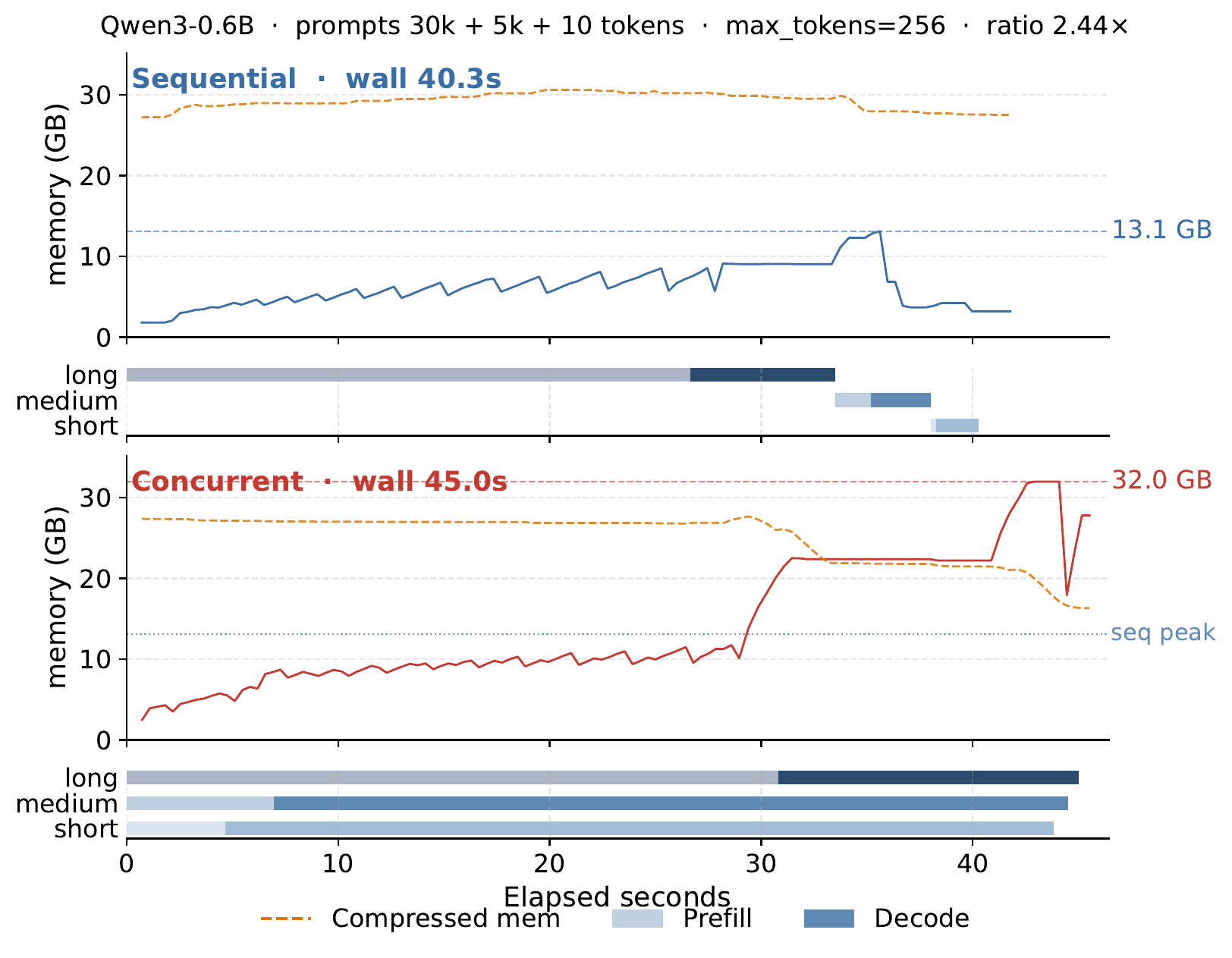
Left: M1 Pro 32GB. Right: M1 Max 64GB. Sequential vs concurrent wall time, with resident memory (solid) and macOS-compressed memory (dashed) over time.
In concurrent mode mlx_lm pads its KV cache to [3, H, 30000, D] because the longest prompt is 30K. The actual tokens total 35,010 (30,000 + 5,000 + 10), but the padded rectangle is 3 × 30,000 = 90,000. 61% of every attention step is wasted on padding. On the 64GB box that padding still fits; resident memory peaks at 32GB and the workload finishes. On the 32GB box the same padded rectangle pushes the system into memory pressure, macOS starts compressing pages (orange line rises from ~2GB to ~6GB), and every decode step pays decompression before attention and recompression after.
This is a deployment cliff: identical code, no OOM, no warning, just silently slower on a smaller machine.
The one layer we replaced
The cliff lives in attention. vllm-metal is a vLLM plugin for Apple Silicon: at the model level it reuses mlx_lm’s weight loader, RMSNorm, Linear, MoE, and MLP layers. All of these are token-wise. They operate on each token independently and don’t care whether tokens are batched as a [B, T] padded rectangle or flattened to a [total_tokens] varlen strip. Attention is the only layer that needs to know about sequence boundaries; that is the one we replaced. Above the model, the scheduler is vLLM’s.
mlx_lm uses flash-style attention over a contiguous, left-padded KV cache shaped [B, H, T, D] (B = batch size, H = number of KV heads, T = sequence length uniform across the batch, D = head dim), consumed by MLX’s stock scaled_dot_product_attention. vllm-metal uses flash-style attention over a paged KV cache laid out as [total_tokens, H, D]: tokens from every sequence are packed onto a single flat token dimension, with cu_seqlens marking sequence boundaries. mlx_lm’s cache is 4D; vllm-metal’s view is 3D, with the [B, T] axes collapsed into a single [total_tokens] axis. The vLLM scheduler drives the varlen layout. Same MLP, different attention.
Why the cliff exists, and what vllm-metal does instead
The cliff is a property of the cache shape.
mlx_lm. The KV cache is a 4D tensor [B, H, T, D] with uniform T. MLX’s stock scaled_dot_product_attention requires this shape and has no cu_seqlens-style parameter; every sequence in the batch occupies T_max tokens whether it needs them or not. Prefill and decode run as mutually exclusive phases. A forward pass is either all prefill or all decode, never mixed. Per-step compute scales as $B \cdot L_{\max}$, so a batch with one long prompt and two short ones pays the long prompt’s price three times.
vllm-metal. The KV cache is paged: KV memory is sliced into fixed-size blocks indexed by a per-sequence block table, the way upstream vLLM does it. Inside the attention step, tokens from all sequences are laid out on a single flat token dimension, with cu_seqlens marking sequence boundaries. The scheduler is free to pack prefill chunks and decode tokens into the same forward pass. This is real continuous batching, not phase-separated pseudo-batching. Per-step compute scales as the total of real tokens, $\sum_b L_b$, so the 90,000 vs 35,010 imbalance from the case study collapses to 35,010. MLX’s stock SDPA accepts neither cu_seqlens nor a block table, so the attention path is a hand-written Metal kernel.
The widget below shows the case-study batch as each layout stores it.
[B, H, T, D] [total_tokens, H, D] cu_seqlens marks the boundariesThe case-study batch as each cache layout stores it. Drag a length: the padded rectangle re-pads everything to the new longest sequence; the packed strip grows only by the tokens actually added.
Speculative decoding falls out for free. Verification scores each sequence’s draft tokens in one forward pass: k + 1 query tokens per sequence, with k varying across the batch, so the batch is ragged on the query axis, not just in KV lengths. To a cu_seqlens kernel this is just another batch. Upstream vLLM’s FlashAttention backend runs prefill, decode, and verification through the same varlen attention call; drafts merely lengthen each request’s query span, and the spec-specific code only picks which logits to verify. After rejection, the diverging accepted prefixes are just new sequence lengths over the same paged store. A 4D padded cache has to re-pad both axes every step, and making that work is involved enough to be its own paper (Batch Speculative Decoding Done Right). vllm-metal has not shipped speculative decoding yet; the layout means it will arrive with no new kernel, just a different cu_seqlens.
On the benchmark
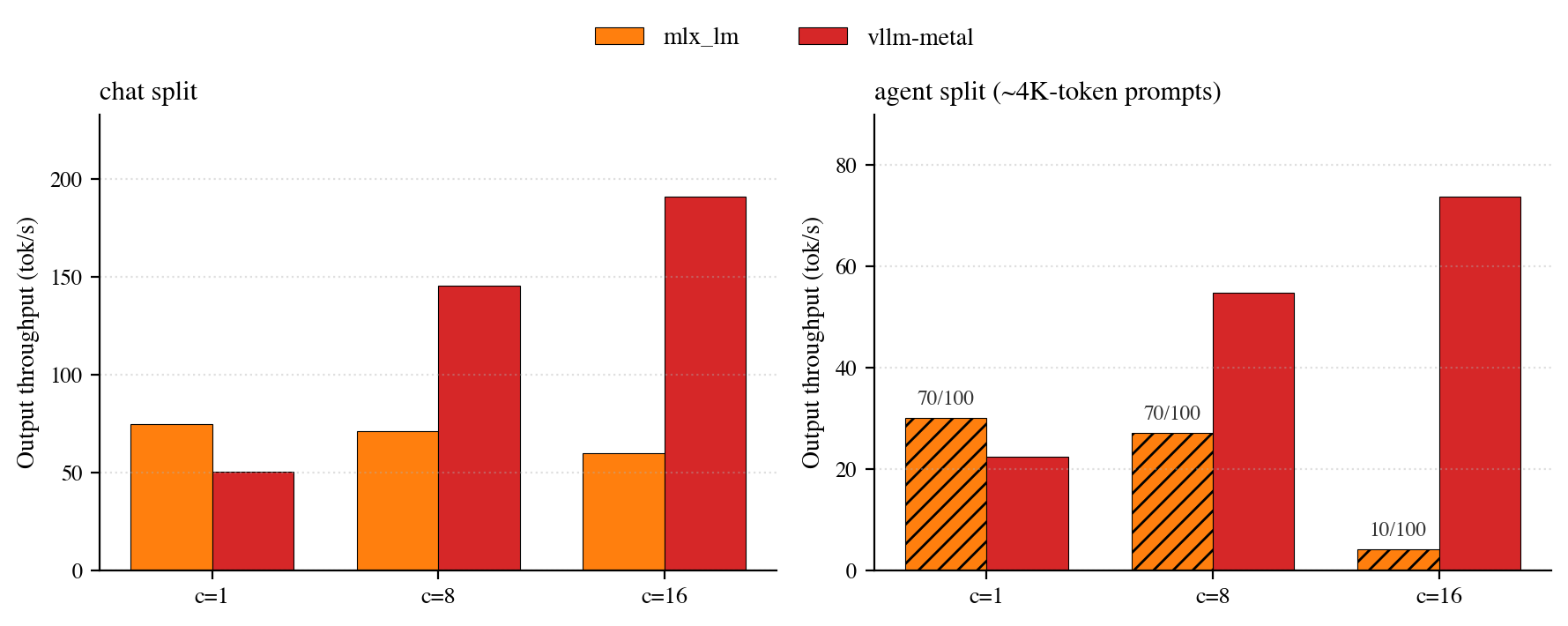
Output throughput (Qwen3-0.6B BF16) on SiliconBench's chat and agent splits at concurrency 1, 8, 16. Hatched mlx_lm bars on the agent split mark partial-success runs (X/100 prompts returned a non-empty completion).
chat split (~1K input, max output 256)
| Engine | c | Success | TTFT p50 (ms) | Throughput (tok/s) | Wall (s) |
|---|---|---|---|---|---|
| mlx_lm | 1 | 100/100 | 201 | 74.7 | 64.5 |
| mlx_lm | 8 | 100/100 | 1382 | 71.1 | 66.8 |
| mlx_lm | 16 | 100/100 | 2014 | 59.5 | 77.1 |
| vllm-metal | 1 | 100/100 | 115 | 50.2 | 92.7 |
| vllm-metal | 8 | 100/100 | 133 | 145.5 | 31.5 |
| vllm-metal | 16 | 100/100 | 183 | 190.8 | 24.1 |
agent split (~4K input, max output 256)
| Engine | c | Success | TTFT p50 (ms) | Throughput (tok/s) | Wall (s) |
|---|---|---|---|---|---|
| mlx_lm | 1 | 70/100 | 628 | 30.1 | - |
| mlx_lm | 8 | 70/100 | 2586 | 27.1 | - |
| mlx_lm | 16 | 10/100 | 33825 | 4.2 | - |
| vllm-metal | 1 | 100/100 | 560 | 22.4 | 269.9 |
| vllm-metal | 8 | 100/100 | 612 | 54.8 | 107.2 |
| vllm-metal | 16 | 100/100 | 736 | 73.8 | 80.4 |
SiliconBench is our benchmark harness for local LLM inference engines on Apple Silicon. It sends 100 prompts to each engine’s OpenAI-compatible API at three concurrency levels: c=1, 8, and 16, where c is the number of in-flight requests. The chat split is single-turn; the agent split is multi-turn material.
At c=1 mlx_lm is faster on both splits. By c=8 the data structure pays off: vllm-metal scales while mlx_lm flattens on chat and collapses on agent.
The agent split also exposes a reliability cliff. mlx_lm returns zero tokens for a large fraction of the long-input prompts at every concurrency level, the same padded-cache problem the M1 Pro experiment isolated, scaled to a benchmark. vllm-metal serves all 100 prompts at all three concurrency levels.
Where this lands in the ecosystem
vLLM’s scheduler is the easy half: it emits a varlen schedule (cu_seqlens and block tables), but the schedule pays off only if that structure survives all the way down to the attention kernel. One repack anywhere in between and you are back to padded compute.
All three MLX-based stacks (mlx_lm, omlx, vllm-mlx) converge at the same MLX call: mx.fast.scaled_dot_product_attention, which requires uniform T and has no cu_seqlens argument. vllm-mlx is worth pointing out: vLLM’s varlen scheduler runs upstream, but a _left_pad_prompts() step at the kernel boundary repacks into 4D padded form. The scheduler is doing varlen bookkeeping the kernel can’t use. llama.cpp takes a third path: its Metal flash-attention kernel supports varlen via an explicit attention mask over per-stream KV ring buffers, with seq_id deciding which tokens attend to which cells.
| Engine | Varlen | KV layout |
|---|---|---|
| mlx_lm | no | 4D padded [B, H, T, D] |
| omlx | no | 4D padded [B, H, T, D] |
| vllm-mlx | no | 4D padded [B, H, T, D] |
| llama.cpp | yes (mask-based) | 3D per-stream ring buffer |
| vllm-metal | yes (cu_seqlens) | 3D flat [total_tokens, H, D] |
Of the five stacks audited, vllm-metal is the only one that pairs cu_seqlens-based varlen with a flat 3D KV layout. On NVIDIA this pairing is the de facto serving pattern. Both vLLM and SGLang use it in production. Apple Silicon hasn’t shipped the same pattern until recently: vllm-metal 0.2.0 (April 2026) is the first end-to-end serving framework on Apple Silicon to ship paged varlen attention. The data-structure choice each stack makes is what shows up at concurrency in the benchmark above.
Citation
This blog post is part of the paper SiliconBench: Speed, Memory, and Fidelity for LLM Inference on Apple Silicon, coming soon to arXiv.